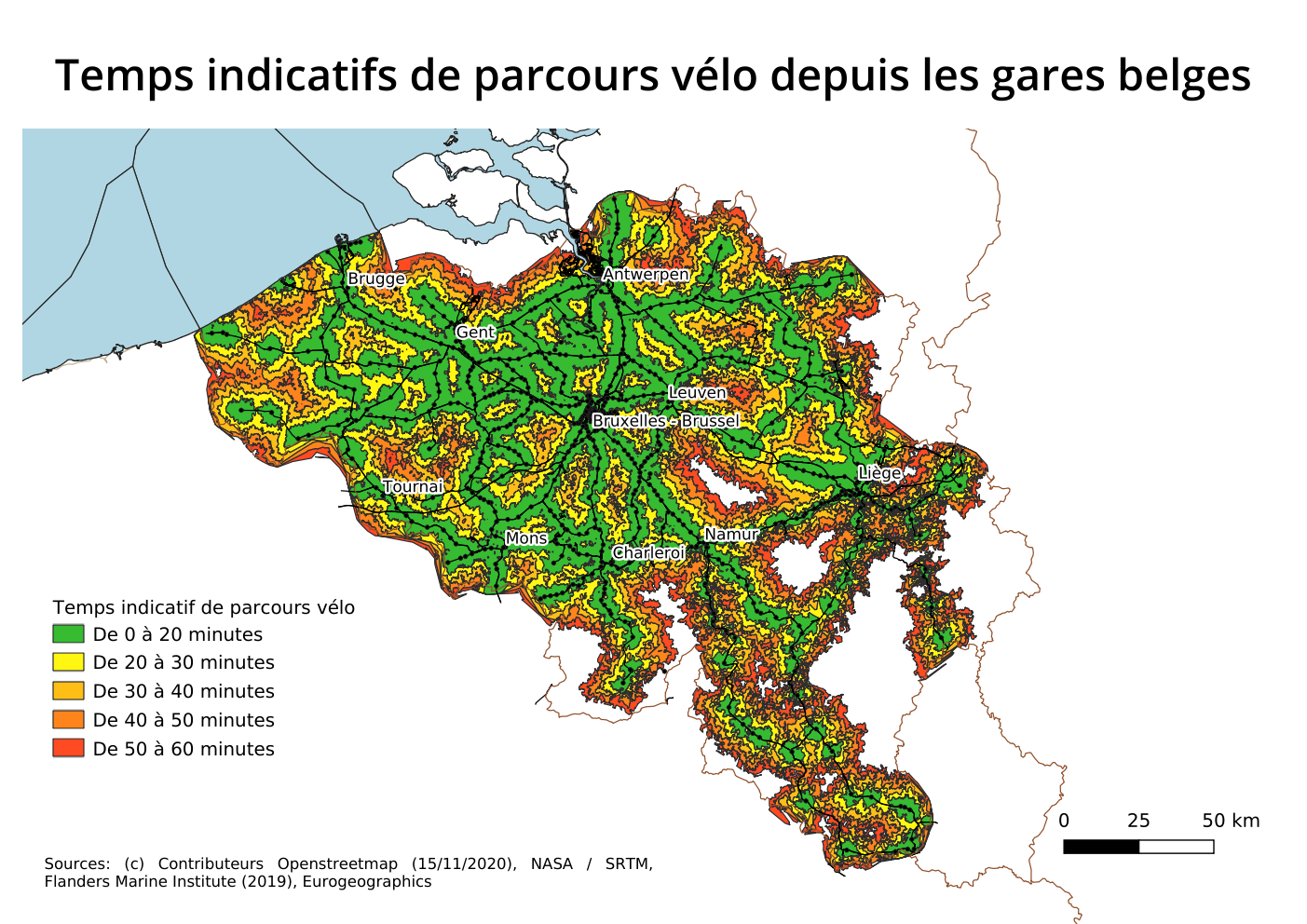
Combien de temps faut-il pour rejoindre la gare la plus proche, en vélo ou à pied ? Si vous êtes - comme nous - des assidus des modes doux, vous vous posez sans doute souvent cette question. Les calculateurs d’itinéraires permettent d’y répondre rapidement.
Mais parfois, cette question se pose de manière globale: quel est l’accessibilité du réseau ferré à pied ou en vélo ? Autrement dit, quel est le territoire desservi à pied et à vélo, dans un temps limite, à partir d’une gare belge ?
Nous proposons ici une méthode de calcul de cette accessibilité. Soucieux de rendre accessible ce résultat au plus grand nombre, nous rendons également disponible les données brutes calculées pour la Belgique. Si vous n’êtes pas féru d’informatique, vous pourrez tout de même ré-utiliser ces données pour mettre en forme vos propres cartes.
Enfin, pour vous faciliter le traitement dans le logiciel cartographique QGIS, nous détaillons quelques difficultés et quelques requêtes utiles pour la mise en forme.
Les données que nous avons calculées sont disponibles sous licence CC-BY-SA: http://opendata.champs-libres.be/isochrones.gpkg. Elles reprennent les informations à notre disposition ce 15 novembre 2020. Lorsque vous ré-utilisez ces données, soyez attentifs à y indiquer la source:
(c) Champs-Libres Cooperative CC-BY-SA, Openstreetmap Contributors, SNCB, NASA
Vous pouvez donc, dans ce billet:
- consulter l’ensemble de la méthode de génération de ces données;
- comprendre les difficultés de représentation de ces données, puis découvrir les requêtes SQL mises en oeuvre pour résoudre ces problèmes;
- ou directement consulter le détail du fichier mis à disposition, et des exemples de requêtes pour exploiter les données traitées.
Vous l’aurez compris, vous pouvez sauter les étapes et ne lire que celles qui vous intéressent.
Calcul des données d’accessibilité
Nous allons calculer l’accessibilité en train et à pied du réseau ferré de la SNCB. Ce calcul va être réalisé pour chaque point d’arrêt reprise dans la liste mise à disposition par la SNCB. Pour chaque point d’arrêt, nous allons dessiner un polygone qui indiquera les zones accessibles à pied et en vélo dans les délais indicatifs suivants: 20, 30, 40, 50, et 60 minutes.
Ces temps de parcours sont indicatifs: certains marcheurs pourront parcourir ces distances dans un temps moindre; un cycliste équipé d’un vélo électrique pourrait être plus rapide.
Pour chaque point autour de la gare, le moteur de calcul indiquera les itinéraires les plus courts en distance. Mais c’est le temps de parcours qui est pris en compte pour poser la limite de l’accessibilité. À vélo, où ce temps de parcours dépend du relief, l’accessibilité est réduit par les montées, et légèrement augmenté en descente. Dès lors, nous effectuerons le calcul dans les deux sens: depuis le point d’arrêt, et vers le point d’arrêt ou la gare.
Nous allons donc utiliser les données suivantes:
- le réseau routier OpenStreetMap (daté au 13 novembre 2020 pour les données fournies);
- la liste des stations de la SNCB, disponible après signature de la licence de distribution (la procédure aura duré deux jours ouvrables pour nous);
- le modèle numérique de terrain SRTM de la NASA, disponible dans le domaine public. Ce modèle est peu précis (précision à 90m), mais s’intègre bien à la chaine d’outil utilisé. Nous l’avons considéré comme suffisant pour cet usage.
Préparation des données
Nous allons préparer les données en utilisant les outils suivants:
- Graphhopper;
- ogr2ogr, inclus dans la suite GDAL;
- LibreOffice, pour nettoyer la liste des gares fournies par la SNCB;
- osmium-tool, pour filtrer les données (optionnel).
Téléchargement des données OpenStreetMap
Les données OSM sont téléchargées sur l’extrait quotidien de Geofrabrik pour la Belgique. Si vous voulez vous restreindre à une région plus petite que le fichier télécharger, ou même pour réaliser les premiers tests, il est recommandé de filtrer les données pour une zone peu étendue. Voici la commande qui le permet, en utilisant l’outil osmium (disponible dans le paquet osmium-tool sous Debian, Ubuntu et dérivés).
# filtrage des données pour l'est de la Wallonie
osmium extract --bbox 3.905640,49.460984,6.503906,51.006842 --output-format pbf --strategy smart --fsync --progress -o wallonie.pbf --set-bounds belgium-latest.osm.pbf
Des outils en ligne permettent de générer facilement la bbox passée en argument. Pensez à vérifier l’ordre des paramètres des limites nord, sud, est et ouest.
Mise en place de Graphhopper
Le fichier de configuration fourni par la documentation est adapté pour télécharger les données du SRTM de la NASA, et préparer uniquement un graphe optimisé pour la circulation à pied et à vélo. Vous pouvez visualiser (et télécharger) notre configuration.
Graphhopper, en version 2.2, peut être téléchargé sous forme d’archive jar. Dès que vous êtes satisfait de votre fichier de configuration, vous pouvez lancer graphhopper avec la commande suivante:
java -jar graphhopper-web-2.2.jar server config.yml
Grapphopper va lire votre fichier de données d’OSM et déterminer leur couverture, puis télécharger automatiquement les données d’élévation suffisantes à cette couverture. Ensuite, il va construire son graphe à partir des données OSM. Pour la couverture “belge”, l’opération a duré moins de quinze minutes sur un PC moyen.
Lorsque vous verrez le message suivant apparaitre dans votre écran, Graphhopper sera prêt:
[main] INFO org.eclipse.jetty.server.Server - Started @671911ms
Vous pouvez tester quelques requêtes en utilisant l’interface web proposée par défaut: http://localhost:8989.
Préparation de la liste des gares
Nous allons maintenant nous concentrer sur la liste des arrêts.
Nous utilisons la liste fournie au sein du GTFS fourni par la SNCB (nous aurions éventuellement pu la remplacer par une requête sur overpass-turbo). Elle demande cependant quelques améliorations, qui sont réalisables avec LibreOffice.
Le fichier GTFS téléchargé est un zip, qu’il est aisé de décompresser. Nous ouvrons le fichier stops.txt comme un fichier CSV, à l’aide de Calc de LibreOffice.
Ensuite, nous avons réalisé les opérations suivantes:
- les gares étrangères ont été enlevées à la main. Elles sont présentes dans les +/- 40 premières lignes;
- pour chaque gare, plusieurs points représentant les voies sont présentes. Nous ne retenons que la gare “principale”, celle dont la colonne
parent_stationest vide. Nous avons donc filtré (à l’aide de l’outil AutoFiltre), puis créé un nouveau fichier CSV par simple copier-coller; - Attention les données de latitude et longitude ont été formatées au format anglais, avec un point (avec l’outil de formatage de LibreOffice). Ceci est important: Graphhopper ne “comprend” l’expression des latitudes et longitudes que sous cette forme.
Nous obtenons donc maintenant un fichier stops.csv qui comporte tous les points d’arrêts de Belgique. En voici un extrait:
stop_id,stop_code,stop_name,stop_desc,stop_lat,stop_lon,zone_id,stop_url,location_type,parent_station,platform_code
101,,Zwijndrecht Dorp,,51.2191923,4.32571361,,,0,,
8811007,,Schaerbeek,,50.87851,4.37864,,,0,S8811007,
La présentation est peu agréable pour un humain, mais convient parfaitement pour les traitements que l’on va réaliser.
Calcul de l’accessibilité
Nous allons mettre en place une boucle en bash pour calculer les isochrones autour de chaque point d’arrêt. Nous utiliserons deux profils préparé: l’un piéton, l’autre cycliste en tenant compte du relief (le profil bike2 proposé par défaut dans Graphhopper).
Pour chacun de ces profils, nous calculerons un isochrone pour différentes temps de déplacement: à 20 minutes, puis 30, 40, 50 et 60 minutes. Graphhopper demandera de les exprimer en secondes: il s’agit donc des temps 1200, 1800, 2400, 3000 et 3600. Pour obtenir le maximum de données brutes, ces calculs seront effectués tant dans le sens de l’aller que du retour (le relief étant différent).
Notez que le fait de conserver un pas régulier entre les différents intervalles (ici, un intervalle de dix minutes) va nous faciliter les requêtes de mise en forme dans QGIS, comme nous l’expliquerons plus loin.
L’api de calcul des isochrones est documentée ici.
La boucle est la suivante:
while IFS="," read -r stop_id stop_code stop_name stop_desc stop_lat stop_lon zone_id stop_url location_type parent_station platform_code
do
echo "processing $stop_name"
echo "place: ${stop_lat},${stop_lon}"
for profile in bike2 foot
do
for t in 1200 1800 2400 3000 3600
do
curl "http://localhost:8989/isochrone?profile=${profile}&reverse_flow=false&result=polygon&time_limit=${t}&point=${stop_lat},${stop_lon}" | jq ".polygons[0]" | jq ".properties += {\"time_limit\": ${t}}" | jq ".properties += {\"stop\":\"${stop_name}\"}" | jq ".properties += {\"profile\": \"${profile}\"}" | jq ".properties += {\"reverse\": false}" > "${stop_name}_${t}_${profile}_reverse_false.geojson"
curl "http://localhost:8989/isochrone?profile=${profile}&reverse_flow=true&result=polygon&time_limit=${t}&point=${stop_lat},${stop_lon}" | jq ".polygons[0]" | jq ".properties += {\"time_limit\": ${t}}" | jq ".properties += {\"stop\":\"${stop_name}\"}" | jq ".properties += {\"profile\": \"${profile}\"}" | jq ".properties += {\"reverse\": true}" > "${stop_name}_${t}_${profile}_reverse_true.geojson"
done
done
done < <(tail -n +2 stops.csv)
Explications:
-
while IFS="," read -r stop_id stop_code stop_name stop_desc stop_lat stop_lon zone_id stop_url location_type parent_station platform_codelit le CSV et place les données dans des variables ($stop_id, etc.); -
deux boucles imbriquées (
for profile in bike2 footetfor t in 1200 1800 2400 3000 3600permettent de procéder aux requêtes pour les deux profils et les intervalles de temps souhaités (exprimés en secondes, soit l’unité requise par graphhopper); -
deux requêtes
curltéléchargent les données de graphhopper.Ces dernières sont retournées en json, les polygones sont décrits dans un format équivalent à geojson, mais imbriqués dans un tableau de
polygons({"polygons:[ <!-- données ici en geojson--> ]}). Pour extraire ces données, nous utilisonsjq:jq ".polygons[0]".Nous ajoutons au geojson obtenu des méta-données: le nom de la station, le profil utilisé, le sens et la limite de temps. Nous utilisons encore
jqpour cela:jq ".properties += {\"time_limit\": ${t}}" | jq ".properties += {\"stop\":\"${stop_name}\"}" | jq ".properties += {\"profile\": \"${profile}\"}" | jq ".properties += {\"reverse\": true}".Ensuite, le fichier sorti (entièrement compatible en geojson) est enregistré dans un fichier avec un nom correspondant aux caractéristiques de la donnée.
-
notons que nous ne lisons pas la première ligne du fichier
stops.csv, qui contient les headers. Nous l’évitons à l’aide de la commandetail -n +2 stops.csv.
L’ensemble de la boucle a été exécutée en un peu moins de deux heures, pour toutes les gares belges.
À la fin, nous obtenons une suite de fichier geojson, tel que celle-ci:
Aalter_1200_bike2_reverse_false.geojson
Aalter_1200_bike2_reverse_true.geojson
Aalter_1200_foot_reverse_false.geojson
Aalter_1200_foot_reverse_true.geojson
Aalter_1800_bike2_reverse_false.geojson
Import au sein d’un geopackage
Nous importons les données en une seule couche et dans un format pratique: un Geopackage. Nous utilisant l’outil ogr2ogr. La commande suivante permet d’effectuer une boucle y compris sur les fichiers qui possèdent des caractères spéciaux ou des espaces:
find . -name "*.geojson" -print0 | while read -d $'\0' file
do ogr2ogr -f GPKG isochrones.gpkg -nln travel_time_to_station -append "${file}"
done
En raison des nombreuses écritures disques, le processus nécessite une grosse dizaine de minutes.
Nous obtenons donc maintenant un fichier isochrones.gpkg avec un couche travel_time_to_station.
Pour chaque couche, les attributs suivants sont disponibles:
geom: la géométrie;time_limit: le temps d’accessibilité;stop: le nom de l’arrêt;reverse: un booleen indiquant s’il s’agit du sens depuis la gare (FALSE) ou vers la gare (TRUE);profile: le nom du profil utilisé.
Mise en forme des données dans Qgis
La mise en forme des données dans QGIS comporte un certain nombre de défis (qu’il est amusant de relever).
Première difficulté: les polygones des isochrones se recouvrent les uns les autres: les parcours les plus courts sont toujours inclus dans un parcours avec un temps de distance plus long. Et les parcours d’une gare proche sont parfois recouverts par les parcours d’une gare lointaine. Dans l’illustration suivante, nous détaillons la zone accessible en un temps court (zone verte), en un temps légèrement plus long (rouge), alors que la zone rouge est accessible en un temps très long:

Il est dès lors complexe de mettre les données en forme “en une seule couche”, ou même en joignant les couches de multiples gares différentes:
-
si elles sont affichées dans un mauvais ordre, les couches des isochrones plus courtes sont recouvertes de celles plus étendues.
Dans le cas où une couche plus petite apparait sous une couche plus grande, elle peut être masquée par les autres couches. Nous l’illustrons ici, où la zone accessible par les temps de parcours les plus rapides (la zone verte) est masquée par la zone des temps de parcours plus long (orange et rouge):

-
Ensuite, une zone éloignée d’une gare (avec un temps de parcours plus long depuis cette gare) peut être plus proche d’une autre gare. Illustration:

Il est donc nécessaire d’afficher le temps de parcours le plus intéressant (et donc celui de la gare proche), sans que les informations de la gare lointaine viennent polluer l’affichage.
Ce calcul n’est d’ailleurs pas uniquement nécessaire pour l’affichage: il peut également être nécessaire pour d’autres traitements (comme, par exemple, une analyse multi-critères).
Nous allons donc effectuer deux traitements:
-
d’abord, nous allons fusionner les polygones qui présentent les mêmes caractéristiques;
-
ensuite, nous allons “enlever” l’intérieur des polygones avec le polygone qui représente l’espace accessible en temps plus court. Pour cela, nous allons utiliser la méthode
ST_difference. Voici une représentation:
Ces opérations peuvent être effectuées directement en SQL, par simplicité (pour rappel, les fichiers geopackages sont basés sur spatialite et SQLite, nous avons donc accès à l’ensemble de ses fonctions.
Application pour un nombre limité de gares
Dans un nouveau projet, nous créons une connection avec le fichier gpkg préparé à l’étape précédente (ou que vous avez téléchargé).
Nous ouvrons ensuite le DB Manager de Qgis: utilisez les menus Base de donnée > DB Manager.... Ensuite, dépliez l’entrée GeoPackage à gauche. Si votre fichier de données n’était pas présent, vous pouvez l’ajouter en utilisant Nouvelle connexion.... Une fois votre fichier sélectionnez, vous pouvez ouvrir un nouvel espace pour introduire votre requête (menu Base de donnée > Fenêtre SQL).
La requête suivante fonctionne pour les gares IC de la ligne Liège-Namur:
WITH times AS (
SELECT ST_union(geom) AS geom, time_limit
FROM travel_time_to_station
WHERE
reverse=0
AND
profile='bike2'
AND stop IN ('Huy', 'Andenne', 'Statte', 'Liège-Guillemins')
GROUP BY time_limit
)
SELECT
ST_difference(times_max.geom, times_min.geom) AS geom,
times_max.time_limit AS max_distance,
times_min.time_limit AS min_distance
FROM times AS times_max
JOIN times AS times_min ON (times_max.time_limit-600) = times_min.time_limit
UNION
SELECT
ST_union(geom) AS geom, 0 AS min_distance, 1200 AS max_distance
FROM times
WHERE time_limit = 1200
Quelques explications:
-
La sélection des éléments qui nous intéresse est effectuée en utilisant les Common Table Expression. En schématisant, cela crée une table temporaire avec nos objets filtrés, table qui peut être ré-tuilisée plus loin. Nous filtrons donc les arrêts, profils, et sens qui nous intéressents.
Cette même requête effectue le regroupement des géométries en une seule, à l’aide de la fonction
ST_Union, qui peut être utilisée dans les requêtes d’aggrégats (même si cela ne fait pas partie du standard OGC).SELECT -- union des géométries ST_union(geom) AS geom, time_limit FROM travel_time_to_station WHERE reverse=0 AND profile='bike2' AND stop IN ('Huy', 'Andenne', 'Statte', 'Liège-Guillemins') GROUP BY time_limit -
Ensuite, les géométries ainsi réunies sont découpées en suivant la forme du polygone plus petit. D’abord, les lignes sont regroupées en utilisant une jointure sur les géométries regroupées au préalable. Cette jointure opère sur la limite de temps inférieure. Comme nous avons utilisé un pas de 600 secondes entre deux limites de temps, et que ce pas est identique, la requête est assez simple:
FROM times AS times_max JOIN times AS times_min ON (times_max.time_limit-600) = times_min.time_limit -
Étape suivante: effectuer la différence entre la zone plus grande et celle plus petite. Nous utilisons simplement la fonction
ST_difference:ST_difference(times_max.geom, times_min.geom) AS geom; -
Enfin, il est nécessaire d’ajouter la zone la plus petite, celle qui n’est jamais découpée par une zone plus petite. Cela est effectué au moyen d’une requête
UNION:SELECT ST_union(geom) AS geom, 0 AS min_distance, 1200 AS max_distance FROM times WHERE time_limit = 1200
Ce qui, après mise en forme, permet de donner une première carte ici:

Cependant, à l’échelle de la Belgique, le temps de calcul est trop long. Nous allons donc préparer ces données au préalable dans une nouvelle couche.
Préparation des données pour la Belgique entière
Nous indiquons ici une méthode pour pré-calculer les données pour la Belgique entière. À la fin de ce processus, nous disposerons donc d’une couche supplémentaire au sein du GéoPackage qui contiendra les polygones à la taille de la Belgique, correctement extrudés par les polygones des distances plus courtes. Il y aura un polygone par sens et profil: la notion de gare de départ sera donc abandonnée.
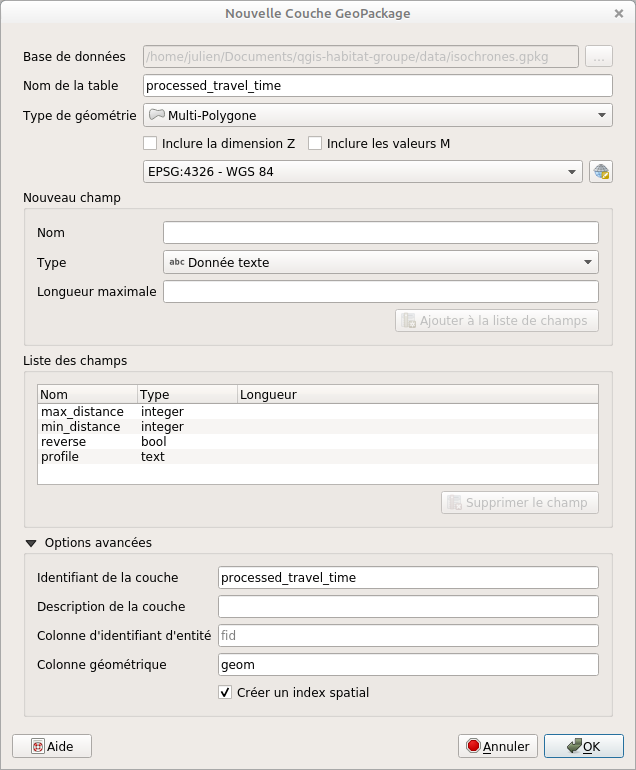
Tout d’abord, il convient de créer la couche dans le fichier GeoPackage. La méthode la plus simple consiste à la créer en utilisant l’interface de QGIS. Cette couche est créée par un simple clic droit sur le nom du Geopackage, dans l’explorateur, ou Couche > Créer une couche > Nouvelle couche Geopackage (sélectionner le même fichier Geopackage que celui qui contient vos données créées à partir de Graphhopper, c’est important !).
Remplissez ensuite la fenêtre avec les informations suivantes (il convient de bien être attentif aux noms de colonnes):
Ensuite, vous pouvez remplir la nouvelle couche à l’aide d’une requête INSERT de SQLite:
WITH times AS (
SELECT ST_union(geom) AS geom, time_limit
FROM travel_time_to_station
GROUP BY time_limit, profile, reverse
)
INSERT INTO processed_travel_time (geometry, max_distance, min_distance, reverse, profile)
SELECT
ST_difference(times_max.geom, times_min.geom) AS geom,
times_max.time_limit AS max_distance,
times_min.time_limit AS min_distance
FROM times AS times_max
JOIN times AS times_min ON (times_max.time_limit-600) = times_min.time_limit
UNION
SELECT
ST_union(geom) AS geom, 0 AS min_distance, 1200 AS max_distance
FROM times
WHERE time_limit = 1200
Comme vous l’aurez noté, il s’agit de la même requête que précédemment, légèrement adapté.
Le calcul a pris une dizaine de minutes sur un poste de travail relativement puissant.
Utilisation dans QGIS
Vous pouvez maintenant utiliser le fichier GeoPackage préparé dans votre projet.
Le fichier généré, s’il est identique à celui que nous partageons, contient donc deux maintenant deux couches:
-
travel_time_to_station, qui contient les polygones complets qui représentent l’espace maximum parcouru dans le temps indiqué par l’attributtime_limit. Les attributs sont donc les suivants:fid: identifiant unique ;time_limit: la durée, exprimée en secondes, qui est la limite maximum de temps nécessaire pour partir ou rejoindre la gare ;stop: le nom du point d’arrêt ;profile: le type de profil: piéton (foot), ou vélo (bike2);reverse: la direction:FALSE(ou0) indique que le parcours provient de la gare pour s’étendre dans l’espace,TRUEou1indique le parcours vers la gare ;bucket: non utilisé ;
Nous avons vu plus haut un exemple de requête pour utiliser ces données pour quelques gares.
-
processed_travel_timeest une couche où les informations sont préparées pour l’étendue de la Belgique, ce qui est nécessaire en terme de performances. Les attributs sont les suivants:profile: le type de profil: piéton (foot), ou vélo (bike2);reverse: la direction:FALSE(ou0) indique que le parcours provient de la gare pour s’étendre dans l’espace,TRUEou1indique le parcours vers la gare ;max_distance, le temps de parcours, exprimé en seconde, qui est la limite maximum de temps nécessaire pour partir ou rejoindre la gare la plus proche, vers tous les points à l’intérieur de ce polygone;min_distance, le temps de parcours en dessous duquel il n’est pas possible de rejoindre un point du polygone à partir de la gare.
Pour les utiliser les données disponible dans processed_travel_time, il est souvent plus utile de filtrer les données en fonction de l’attribut reverse et profile (pour ne voir que les données pour un profil et dans un sens particulier). Voici quelques exemples de requêtes que vous pouvez utiliser dans le DB Manager de QGIS (pour rappel, vous pouvez y accéder en utilisant les menus suivants: Base de données > DB Manager... puis cliquez sur la couche correspondante dans le GeoPackage, et ouvrez une fenêtre SQL: Base de donnée > Fenêtre SQL):
-- trajets depuis la gare vers les points de destination, profil piéton
SELECT * FROM processed_travel_time WHERE reverse = 0 AND profile = 'foot';
-- trajets depuis la gare vers les points de destination, profil cycliste
SELECT * FROM processed_travel_time WHERE reverse = 0 AND profile = 'bike2';
-- trajets depuis les points de destination, vers la gare, profil piéton
SELECT * FROM processed_travel_time WHERE reverse = 1 AND profile = 'foot';
-- trajets depuis les points de destination, vers la gare, profil cycliste
SELECT * FROM processed_travel_time WHERE reverse = 1 AND profile = 'bike2'
Si vous utilisez ces données, n’hésitez pas à nous en faire part et à nous montrer vos mises en formes.
Happy mapping!
